
Общая информация по сервису DRAAS на базе VEEAM
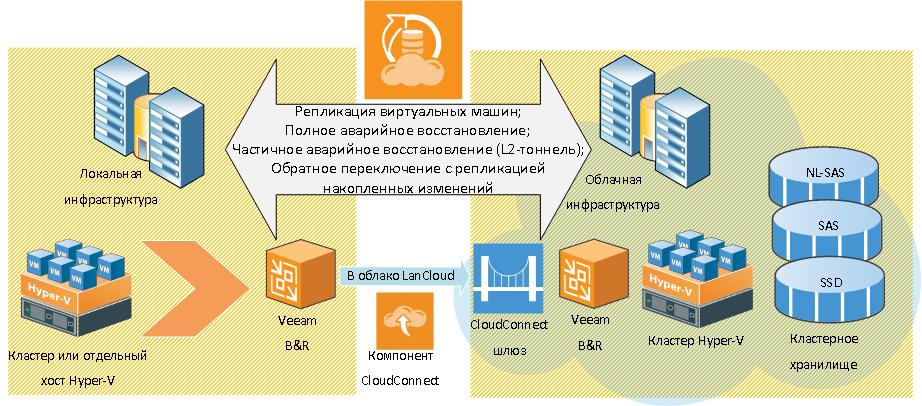
Сервис позволяет:
- реплицировать в облако Hyper-V виртуальные машины заказчика на базе Veeam Backup&Replication с помощью технологии Cloud Connect (далее – VBR CC);
- реализовать концепцию основного сайта и облачного сайта аварийного восстановления (далее — DR site);
- выполнять частичное аварийное восстановление основной инфраструктуры заказчика в облако, при котором основная и резервная площадки взаимодействуют друг с другом с помощью прозрачного L2 VPN-тоннеля (далее — partial failover);
- выполнять полное аварийное восстановление всей инфраструктуры основной площадки в облако (далее — full failover);
- выполнять обратное переключение из облака в продуктив с репликацией всех накопленных изменений за время аварии (далее – failback);
- заказчику самостоятельно создавать и тестировать планы восстановления (далее – failover plan).
Возможности клиента в контексте DRAAS
Клиент может выполнять следующие административные действия:
- Тестировать failover в облако из клиентской консоли VBR. При этом существующая инфраструктура не отключается и L2 VPN-тоннель не поднимается. Здесь выполняется проверка консистентности реплик в облаке, пинги и т.п..
- Инициировать процедуру partial failover из клиентской консоли VBR. При данной процедуре автоматически поднимается L2 VPN тоннель и обе площадки начинают видеть друг друга. Выбранные реплики виртуальных машин заказчика запускаются в облаке. Следует отметить, что VBR не выключает виртуальные машины на стороне клиента, и он это должен это учитывать сам.
- Инициировать процедуру full failover из клиентской консоли VBR. При данной процедуре L2 VPN тоннель не имеет смысла. Все реплики виртуальных машин заказчика запускаются в облаке.VBR не выключает виртуальные машины на стороне клиента. Данная процедура сложна тем, что необходимо планирование и тестирование шлюза для DR-сайта.
- Инициировать процедуру преобразования DR-сайта в основной сайт – permanent failover. При этом виртуальные машины в облаке перестают реплицировать изменения из других площадок. Возможно только для случая full failover в рамках failover plan.
- Инициировать процедуру undo failover без коммита накопленных изменений. При данной процедуре реплики в облаке просто выключается. Также выключаются обе NEA виртуальных машины, если это был partial failover.
- Инициировать процедуру failback обратно в продуктив с коммитом накопленных в облаке изменений. При этом виртуальные машины выключаются для консолидации реплики. После failback’а тоннель деактивируется, если он был поднят.
- Создавать планы восстановления или failover plans и тестировать их. Можно создать несколько планов и включить в них разные машины с разным временем одновременного запуска и скриптами.
- Если VBR-консоль не доступна, а также в случае недоступности всей клиентской VBR-инфраструктуры, заказчик может через веб-интерфейс Veeam Enterprise Manager (далее — VEM) у провайдера выполнять full failover, предварительное создав и настроив failover plan, т.к. для частичного восстановления нужна рабочая VBR-среда заказчика.
Основные сценарии
Частичное аварийное восстановление или partial failover
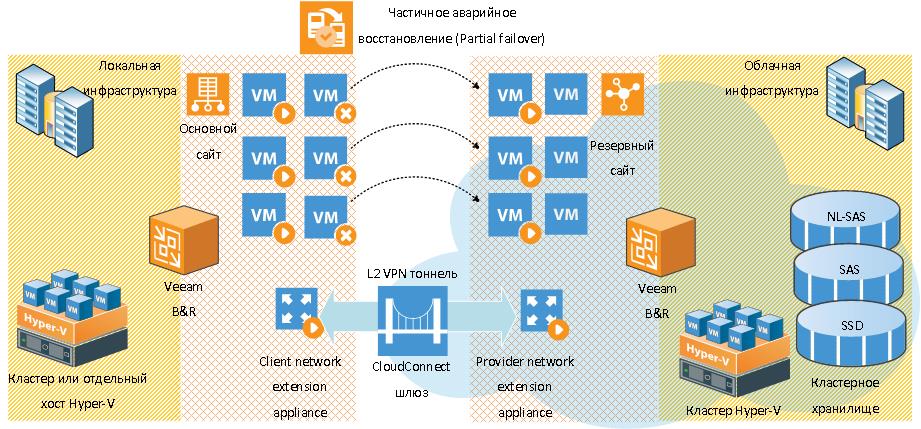
При данном сценарии подразумевается, что часть виртуальных машин заказчика оказались недоступными. Заказчик из консоли VBR выбирает отказавшие машины и выполняет процедуру partial failover. При этом автоматически запускаются нужные реплики в облаке, NEA-виртуальные машины на обоих концах, и поднимается L2-тоннель. Обе площадки видят друг друга. Все виртуальные машины заказчика в облаке работают в автоматически назначенном влане. Взаимодействие между площадками осуществляется через провайдерский cloud connect шлюз. Следует учитывать, что при данной процедуре VBR не включает/выключает никакие виртуальные машины на стороне клиента, кроме NEA. По завершении процедуры заказчик может сделать undo failover – при этом все реплики в облаке выключатся, а тоннель деактивируется. Также заказчик может выполнить процедуру failback с коммитом накопленных изменений из облака в основную площадку. Виртуальные машины при failback выключаются. Failback осуществляется в обход L2-тоннеля, по сути, это обратная репликация из облака в основную площадку средствами VBR. Если VBR-инфраструктура недоступна failback невозможен.
Маршрутизация и доступ в Интернет при частичном аварийном восстановлении
После отработки partial failover NEA на стороне клиента и NEA на стороне провайдера через облачный шлюз veeambackup.lancloud.ru между собой организуют L2-тоннель, организующий нечто вроде распределенного коммутатора, в который подключены все ресурсы обеих площадок. Трафик в Интернет, а также публикации с перспективы DR-сайта идут через шлюз на основной площадке, если он доступен.
Основные сценарии
Полное аварийное восстановление или full failover
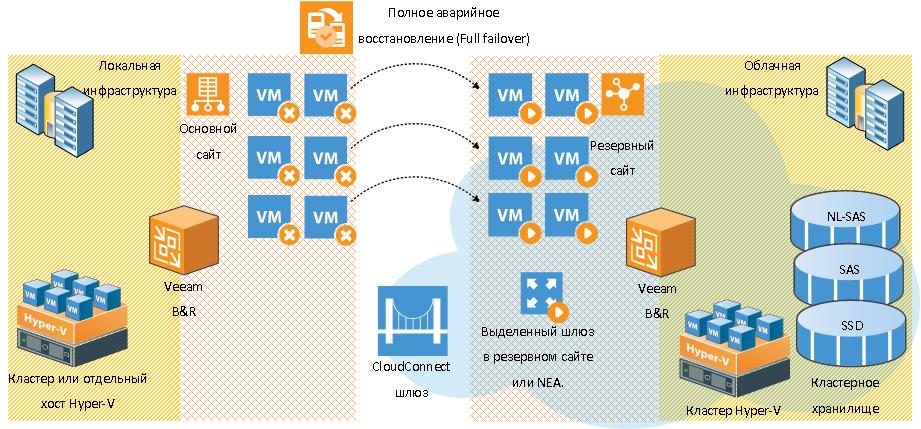
При данном сценарии заказчик или провайдер инициирует из консоли VBR-процедуру full failover. При этом все реплики в облаке запускаются. Шлюз в резервном сайте запускается отдельно, чтобы DR-инфраструктура взаимодействовала с внешним миром. После восстановление основной площадки также возможен failback с коммитом накопленных изменений из облака в продуктив. В данном сценарии VBR также не управляет виртуальными машинами в инфраструктуре заказчика. Понятия L2-тоннеля в данном сценарии нет. Если VBR-консоль или вся VBR-инфраструктура заказчика не доступны, то можно инициировать failover через VEM, а также попросить провайдера сделать это или через iaas панель…
Маршрутизация и доступ в Интернет при полном аварийном переключении
Существует два варианта.
Первый вариант ручной и гарантированный с предварительно сконфигурированным шлюзом и настроенными публикациями. Подходит для сложных инфраструктур с множеством различных сетей и сложной топологией.
Второй вариант автоматический, но подходит для относительно простых инфраструктур. Этот вариант представлен ниже.
При полном аварийном переключении NEA на стороне провайдера может являться шлюзом для всех виртуальных машин в DR-сайте. Также NEA может публиковать сервисы, вплоть до назначения разных IP и портов. Настраивается это на стороне клиента в рамках сущности failover plan. Если инициируется отработка такого failover plan, то провайдерский NEA будет являться шлюзом и публикатором сервисов для всех виртуальных машин тенанта.
Машины, которые аварийно переключаются вне предварительно сконфигурированного заказчиком failover plan’а, доступа в Интернет иметь не будут, не говоря уже о каких-либо публикациях. Для таких случаев нужно конфигурировать отдельный шлюз в облаке со всеми вытекающими последствиями.
По завершении такого full failover, NEA на стороне провайдера:
- Автоматически получает внешний IP из выделенного провайдером пула.
- Становится шлюзом для всех виртуальных машины заказчика в DR-сайте и пускает их в Интернет.
- Публикует сервисы согласно failover plan, который настроил заказчик.